【Python】tabula.read_pdfでDataFrameにどんなデータが取得されるか
tabula-pyを使って複数の表が記載されたpdfファイルをDataFrameへ読み込んだ時どんな感じになっているのか、VSCodeでステップ実行したときのメモ。
表が複数掲載されたpdfファイルを仮に用意。今回は以下のようなもの。

下記のようなシンプルなコードにブレークポイントを設定してデバッグ実行してみる。
import pandas as pd import tabula pdffile1="d:\複数テーブル.pdf" dfs = tabula.read_pdf(pdffile1, lattice=True , pages = 'all') for df in dfs: print(df) print('complete!')
まずはdfsに何が入っているかを見るために、dfs=tabula.read_pdf(...)で受け取るところまで実行して、変数dfsを右クリック⇒「データビューアで値を表示」。

データビューアで変数dfsの中身を見てみると、表がリスト化されて入っているのがわかる。ちなみにPythonにおける「リスト」はデータを一直線にまとめたもの。
ここでは3つの表が掲載されたpdfだったので、3つのリストが表示される。

さらに今度はfor df in dfs:まで実行してから変数dfをデータビューアで見てみると
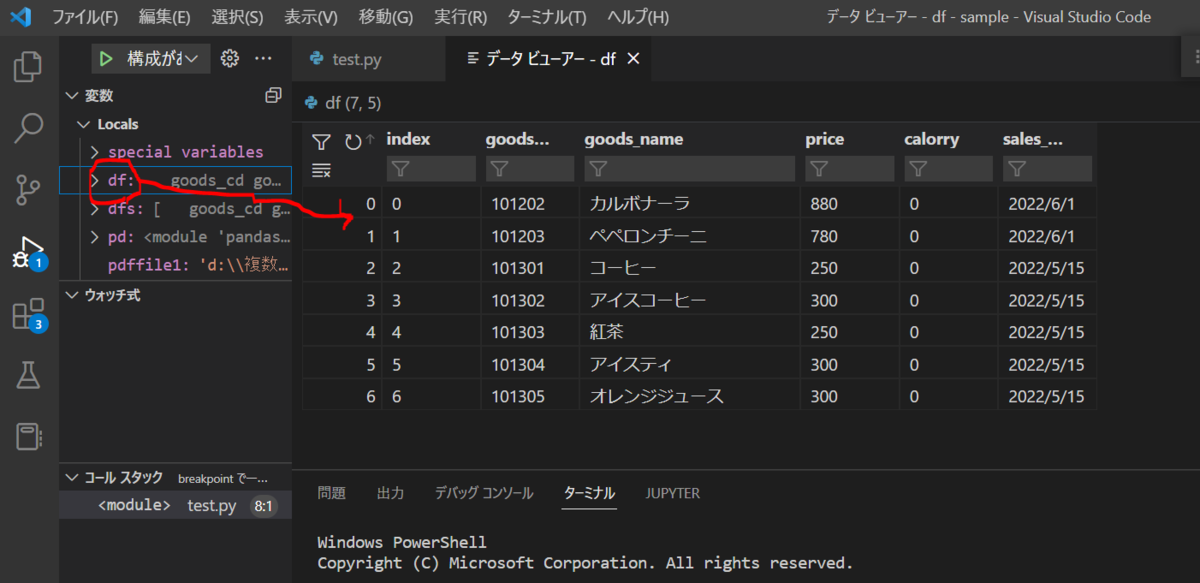
1つめのリストがテーブルとして表示されたもの。
もちろんdf[0]をprintでみたらこれと同じ内容を見ることがでかきるが、printでターミナルに表示されたものには罫線がないためわかりにくいことに加え、カラム名とデータ部分の列幅がきれいに合わないこともある。「データビューアで値を表示」はきちんと表形式で確認できるのでこちらがよい。
ということで、複数の表が掲載されたpdfを読み込ませるとdf[0]、df[1]、df[2]に読み込まれる。表外に書かれたタイトル部分は読み込まれない。

以上。